TableNet: A Deep Learning model for Table detection and Tabular data extraction from Scanned Document Images|| An End To End Implementation

Tables are used frequently to represent data in a clean format. We can see them so often across several areas, from organizing our work by structuring data across tables to storing huge assets of companies. There are a lot of organizations that have to deal with millions of tables every day. To facilitate such laborious tasks of doing everything manually, we need to resort to faster techniques.
This Case Study deals with detection of tables in scanned images (let for instance Marmot Data). The architecture is based out of Long et al., an encoder-decoder model for semantic segmentation. The images are preprocessed and modified using the Tesseract OCR.
How is table extraction done? Exactly what is the real world significance of it?
Detecting tables in documents is important since not only do the tables contain important and relevant information, but also most of the layout analysis methods fail in the presence of tables in the document images.

Lets Get Started folks!!👊
TABLE OF CONTENTS :
— Business Problem
— Business Objectives and Constraints
— Source of Data and Dataset Description
— Problem Formulation
— Performance Metrics
— Towards Data Preparation
— TableNet Architecture
— Post Training Quantization
— Optical Character Recognition(OCR)
— Data Extraction in CSV file
— Model Deployment
— Further Improvements
— References
BUSINESS PROBLEM
Tables are used frequently to represent data in a clean format. We can see them so often across several areas, from organizing our work by structuring data across tables to storing huge assets of companies. There are a lot of organizations that have to deal with millions of tables every day. To facilitate such laborious tasks of doing everything manually, we need to resort to faster techniques
This Case Study deals with detection of tables in scanned images (let for instance Marmot Data). The architecture is based out of Long et al., an encoder-decoder model for semantic segmentation. The images are preprocessed and modified using the Tesseract OCR.

BUSINESS OBJECTIVES AND CONSTRAINTS
Now that the Business Problem is clear , we need to identify the associated business objectives and constraints. This is the most important part before moving forward to formulating the Machine Learning Problem, as they would define the kind of solution that we would need to develop.
OBJECTIVES
To detect tables if present in a scanned document image and further extract the information in the tables detected.
CONSTRAINTS
Now that the Problem Statement is clear , we need to identify the associated business constraints. This is the most important part before moving forward to formulating the problem, as it would define the kind of solution that we would need to develop.
- Model Interpretability is not required. We just require the exact table and the corresponding data to get extracted. How, is not a concern.
- No strict Latency requirements, as the objective is more about making the right prediction rather than a quick decision. It would be fine and acceptable if the model takes few seconds to make a prediction.
- But the metric (accuracy/f1 score) should be high.
SOURCE OF DATA
The data has been taken from the following link::
https://drive.google.com/drive/folders/1QZiv5RKe3xlOBdTzuTVuYRxixemVIODp
DATASET DESCRIPTION
The pages in PDF format were collected and the corresponding ground-truths were extracted utilizing the semi-automatic ground-truthing tool “Marmot”.
- The pages were selected from over 120 e-Books with diverse subject areas provided by Founder Apabi library, and no more than 15 pages were selected from each book.
- The English pages were crawled from Citeseer website.
The pages show a great variety in language type, page layout, and table styles. Among them, many conference and journal papers were crawled, covering various fields, spanning from the year 1970, to latest 2011 publications.
The e-Book pages are mostly in one-column layout, while the English pages are mixed with both one-column and two-column layouts.

PROBLEM FORMULATION
We can identify that it is a Classification problem, whether the table has been predicted correctly or not
We’ll be computing the table and column masks based on which tables can be detected and the data retrieved.

PERFORMANCE METRICS
We can use Accuracy/F1 Score to verify our predictions.
TOWARDS DATA PREPARATION
Firstly we need to perform XML Parsing. We need to have tabular coordinates (xmin, xmax, ymin, ymax) using the XML file to detect masks.
Now coming to the generation of table and column masks;
Here we leverage the min/max bndbox coordinates and the masked portion of image (table) is given the value 255 as compared to the rest of the part having value 0.
For column detection within tables, we take into account all the bndbox coordinates in the lists we formed .Just like table masks, here we too give value 255 for the masked portion
Now we can just view our files;



Now we’ll perform Normalization, Resizing to 1024 resolution,and finally fitting the data into the Tablenet Architecture

TABLENET ARCHITECTURE
1. The model is derived in two phases by subjecting the input to deep learning techniques. They’ve used the weights of a pretrained VGG-19 Network. They’ve replaced the fully connected layers of the used VGG network by 1x1 Convolutional layers.
2. All the convolutional layers are followed by the ReLU activation and a dropout layer of probability 0.8. They call the second phase as the decoded network which consists of two branches. This is according to the intuition that the column region is a subset of the table region.
3. Thus, the single encoding network can filter out the active regions with better accuracy using features of both table and column regions.
4. The output from the first network is distributed to the two branches. In the first branch, two convolution operations are applied and the final feature map is upscaled to meet the original image dimensions.
5. In the other branch for detecting columns, there is an additional convolution layer with a ReLU activation function and a dropout layer with the same dropout probability as mentioned before.

For implementing the TABLENET architecture, I have implemented using VGG19 and RESNET50 as base models. I shall be discussing both the approaches here.
VGG19 as base model

Resnet50 as base model
When loading a given model, the “include_top” argument can be set to False, in which case the fully-connected output layers of the model used to make predictions is not loaded, allowing a new output layer to be added and trained
Now, coming to the results before the actual training;

After the training took place;


Lets have a look at the Accuracy and Loss after the model was trained;

POST TRAINING QUANTIZATION
Post-training quantization is a conversion technique that can reduce model size while also improving CPU and hardware accelerator latency, with little degradation in model accuracy. You can quantize an already-trained float TensorFlow model when you convert it to TensorFlow Lite format using the TensorFlow Lite Converter

So as a result of Post Training Quantization, My Model size reduced from 81.76 MB to 20.81 MB. (4 times )
OPTICAL CHARACTER RECOGNITION(OCR)
I am using pytesseract. Python-tesseract is an optical character recognition (OCR) tool for python. That is, it will recognize and “read” the text embedded in images.

Python-tesseract is a wrapper for Google’s Tesseract-OCR Engine. It is also useful as a stand-alone invocation script to tesseract, as it can read all image types supported by the Pillow and Leptonica imaging libraries, including jpeg, png, gif, bmp, tiff, and others. Additionally, if used as a script, Python-tesseract will print the recognized text instead of writing it to a file.



EXTRACTING THE DATA IN THE TABLE AND STORING IT IN A CSV FILE

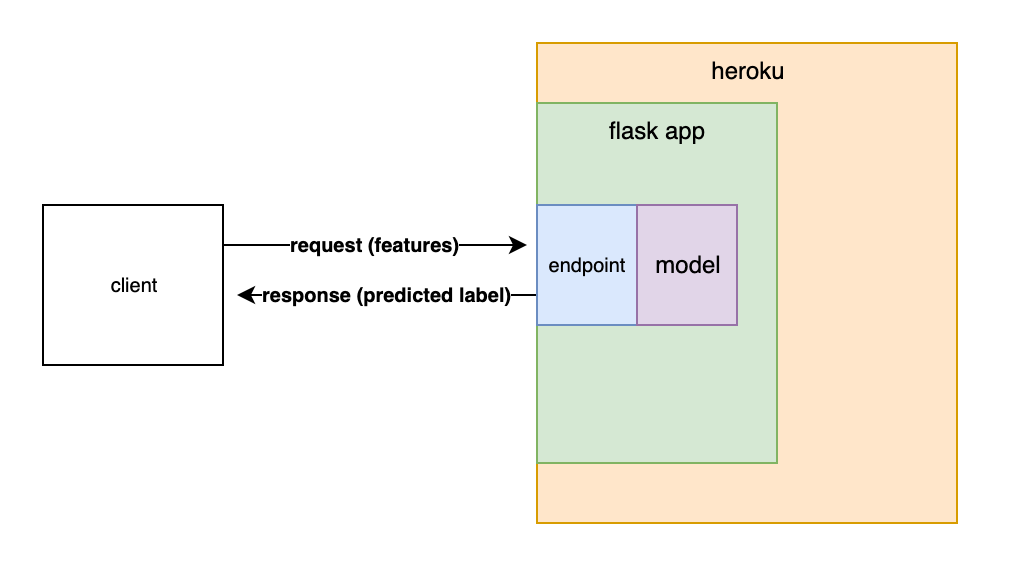
MODEL DEPLOYMENT
We tend to forget our main goal, which is to extract real value from the model predictions.
Deployment of models or putting models into production means making your models available to the end users or systems. Here I used the Flask API to deploy my model in my local system.

Here’s a video showing the deployed model and its working
FURTHER IMPROVEMENTS
A large data corpus would indeed give quite good results. Marmot dataset is quite small to give high quality results here.
Due to GPU limitations, the process is limited to a certain resolution images here. So training on high resolution images is the need of the hour.
Training on more number of epochs will definitely yield better results as stated in the paper
GitHub Profile:
https://github.com/PranjalDureja0002/Health_Fraud
LinkedIn Profile:
https://www.linkedin.com/in/pranjal-dureja-89409a1a5/
REFERENCES
https://arxiv.org/pdf/2001.01469.pdf
https://github.com/jainammm/TableNet/blob/master/TableNet.ipynb

{kind=link}